이전 시간에는 데이터 링크 계층에 대해 알아봤습니다.
오늘은 네트워크 계층에 대해 작성해보려고 합니다!
네트워크 계층
네트워크 계층은 데이터를 목적지까지 가장 빠르게 전달하는 역할을 수행하는 계층입니다. 라우터를 통해 라우팅을 하며 컴퓨터의 위치를 나타내기 위해 IP주소가 사용됩니다.
네트워크 계층은 내용이 많으니 천천히 읽으면서 따라와 주세요!
- 데이터 전송 과정
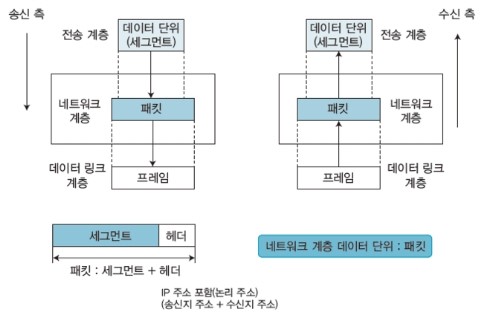
위의 그림은 네트워크 계층에서 데이터가 전송되는 과정입니다. 송신 측에서는 전송 계층에서 받은 데이터에 헤더를 붙여 데이터 링크 계층으로 보내고, 수신 측에서는 데이터 링크 계층에서 받은 데이터에 헤더를 제거하여 전송 계층으로 보냅니다. 네트워크 계층의 데이터는 패킷이라고 하며, 헤더에는 송신 측 IP 주소와 수신 측 IP 주소 등이 포함됩니다.
- IP 주소
이전 게시물에서 Mac주소에 대해 설명할 때 IP주소도 설명했어서 익숙하시겠지만 IP주소는 컴퓨터간 통신을 하기 위해 사용되는 네트워크 상 주소입니다. 아래 파란 박스 안에 있는 숫자들이 IP주소이며, 2진수로 구성된 4개의 필드(초록색 원)가 점(.)으로 구분되어 있습니다. 파란 박스 위에 있는 "172.16.254.1" 으로 표현된 IP주소가 익숙하실 텐데 2진수로 표현된 IP주소를 사람이 이해하기 쉬운 10진수로 표현한 것입니다. 2진수를 10진수로 변환한 것이기 때문에 1개의 필드당 10진수로는 최대 255까지(2진수로는 11111111) 표현이 가능합니다.
IP주소를 보면 네트워크 상에서 해당 컴퓨터가 어디 있는지 알 수 있습니다. IP주소가 어떻게 컴퓨터의 위치를 나타낼 수 있을까요?

컴퓨터의 위치를 나타내기 위해서 IP주소는 네트워크 부분과 호스트 부분으로 나뉠 수 있습니다. 네트워크 부분은 호스트가 속한 네트워크 부분이 어딘지를 나타내고 호스트 부분은 해당 네트워크의 어느 호스트인지를 나타냅니다. 위의 IP주소에서 172.16가 네트워크 부분이고 254.1이 호스트 부분이라면 저 IP주소의 의미는 주소가 172.16인 네트워크의 254.1번 호스트(=컴퓨터)라고 할 수 있습니다.
예를 들어보겠습니다. 택배를 보낼 때 받는 사람의 주소를 "서울시 강남구 논현동 A번지"라고 썼다면 택배기사님은 "서울시 강남구 논현동"이라는 구역에 가서 "A번지"를 찾아 택배를 배달할 겁니다. 즉, "서울시 강남구 논현동"이 네트워크 부분, "A번지"가 호스트 부분이라고 할 수 있습니다.
그럼 네트워크 부분하고 호스트 부분은 어떻게 구분할까요?
- 네트워크 부분과 호스트 부분
(1) 클래스
아래의 표는 각 클래스를 정리한 표입니다. 위의 IP주소 "172.16.254.1"을 설명할 때 네트워크 부분을 "172.16", 호스트 부분을 "254.1"이라고 했는데 왜 그렇게 설명했는지 아시겠죠? "172.16.254.1"가 B클래스에 속한 IP주소이기 때문입니다.
| 클래스 | 네트워크/호스트 | 시작주소 ~ 마지막주소 |
| A클래스 | 1번째수 / 2, 3, 4번째수 | 0.0.0.0 ~ 127.255.255.255 |
| B클래스 | 1, 2번째수/ 3, 4번째수 | 128.0.0.0 ~ 191.255.255.255 |
| C클래스 | 1, 2, 3번째수 / 4번째수 | 192.0.0.0 ~ 223.255.255.255 |
A클래스를 보면 네트워크는 0~127개 밖에 안되지만 호스트의 범위가 엄청 넓습니다. 하나의 네트워크에 연결된 컴퓨터가 많은 경우에 적합합니다. 반대로 C클래스를 보면 네트워크 범위는 넓지만 각 네트워크당 호스트로 지정할 수 있는 범위가 좁습니다. 하나의 네트워크에 연결된 컴퓨터가 많지 않은 경우에 적합합니다. 예를 들면 서울처럼 한 지역에 사람이 밀집된 경우는 A클래스에 적합하고, 한적한 지역은 C클래스에 적합합니다.
클래스로 구분하는 것은 간단하지만 지금은 사용되지 않는 방법입니다. 왜 그럴까요? 사실 A클래스에 속한 네트워크 중에 호스트가 꽉 차지 않은 네트워크도 있습니다. 호스트의 범위가 너무 넓기 때문입니다. 현재 전 세계의 네트워크량이 계속 증가하고 있기 때문에 IP주소는 부족한 상황인데 A클래스에 속할 정도로 대규모 네트워크는 많지 않아 IP주소가 낭비되고 있는 것입니다. 그래서 비효율적이어서 지금은 사용되지 않는 방법이기 때문에 클래스를 깊게 공부하실 필요는 없습니다.
(D클래스와 E클래스도 존재하지만 특수 목적을 위한 클래스여서 그런게 있다 정도만 아시면 됩니다.)
(2) 서브넷
클래스 방식은 필드 별로 네트워크와 호스트가 나뉘기 때문에 사용되지 않는 IP주소 많습니다. 이를 해결하기 위해 등장한 것이 서브넷팅입니다. 클래스는 필드를 기준으로 나누지만 서브넷팅은 비트 단위로 나뉠 수 있습니다. 다시 말해서 클래스가 3가지의 경우로 나뉘었다면 서브넷(분활된 네트워크)은 총 31가지의 경우로 나뉘게 되는 것입니다. 서브넷의 경우는 비트 단위로 나뉘기 때문에 어디까지가 네트워크이고 어디까지가 호스트인지 구별할 수 있는 식별자가 필요한데, 이를 서브넷 마스크라고 합니다.
서브넷 마스크는 IP주소처럼 2진수 32비트로 구성되어있고, 사람이 이해하기 편하게 10진수로 변환하여 표기합니다. 만약 서브넷 마스크가 "255.255.254.0"라면 몇 번째 비트까지가 네트워크 부분일까요?? 2진수로 변환하면 쉽게 알 수 있습니다.
10진수 : 255.255.254.0 => 2진수 : 11111111.11111111.11111110.00000000
2진수로 변환된 서브넷 마스크를 보면 23비트까지는 1로 구성되어 있고 나머지 9비트는 0으로 구성되어 있습니다. 1로 구성된 부분이 네트워크 부분이고 0으로 구성된 부분이 호스트 부분으로, 2진수로 표현하는 순간 네트워크와 호스트 구분이 쉬워집니다.
서브넷 마스크를 표현하는 방식은 방금 본 10진수 표기법 말고도 프리픽스 표기법이 있습니다. "192.255.255.2/23" 이 프리픽스 표기법으로 표현한 것으로, 앞의 주소는 IP주소이고 슬래시(/) 이후 "23"이 네트워크 부분의 비트 수를 표현한 것입니다.
- 라우팅과 라우터
라우팅이란 통신을 할 때 최적의 경로를 찾아 데이터를 전송하는 과정을 말합니다. 이때 라우터가 사용되며 라우터는 능동적으로 라우팅을 수행하는 장비입니다. 즉, 패킷이 라우터에 들어오면 순간순간 최적의 경로를 탐색하여 패킷을 전송하는 장비입니다.
라우터는 라우팅 테이블을 가지고 라우팅을 수행합니다. 라우팅 테이블은 목적지까지 가기위해 다른 라우터의 정보를 가지고 있는 것으로 지도라고 생각하면 됩니다.

위의 그림은 저번 시간에 설명한 스위치에 라우터까지 연결된 모습을 나타낸 것으로, 파란 박스가 스위치로 연결된 LAN이고 전체적인 네트워크가 WAN입니다.
PC0에서 PC5로 데이터를 전송한다면 PC0과 연결된 스위치를 지나 Router0에 도착하게 됩니다. Router0에서는 라우팅 테이블(=지도)을 통해 데이터를 Router2로 전송하게 되고 Router2에서 PC5로 데이터가 전달되게 됩니다.
- 라우팅 방법
경로를 찾는 방법은 정적 라우팅과 동적 라우팅 2가지 방법이 있습니다.
(1) 정적 라우팅
사람이 직접 패킷의 경로를 임의로 결정하여 데이터를 전송하는 방법입니다. 사람이 경로를 정하기 때문에 라우터의 할 일이 적어져서 라우터의 부하가 줄어듭니다. 하지만 그만큼 사람의 할 일이 많아진다는 단점이 있습니다. 또한 정해진 경로에 문제가 발생할 경우 데이터 전송에 장애가 발생할 수 있습니다.
(2) 동적 라우팅
라우터가 라우팅 테이블의 정보를 가지고 스스로 라우팅 경로를 결정하는 방법입니다. 사람이 직접 경로를 결정하지 않기 때문에 부담이 적고 매번 최적의 경로를 탐색하기 때문에 데이터 전송 중 장애가 발생할 일이 적습니다. 하지만 라우터의 부하가 크다는 단점이 있습니다.
동적 라우팅 알고리즘으로는 벨만 포드(Bellman-Ford) 알고리즘과 다익스트라(Dijkstra) 알고리즘이 있습니다. 두 알고리즘 모두 최단 경로를 선택하는 방법으로 만약 A->B로 갈 때 A->B로 가는 비용보다 A->C->B로 가는 비용이 적게 든다면 A->C->B로 가는 방법을 선택하는 알고리즘입니다. 차이점은 다익스트라 알고리즘은 매번 방문하지 않은 노드 중에서 최단 거리가 가장 짧은 노드를 선택한다면 벨만 포드 알고리즘은 매번 모든 노드를 확인하면서 가장 짧은 노드를 선택합니다.
(이번 게시물은 네트워크에 관한 게시물이므로 최단거리 알고리즘에 대한 자세한 설명은 아래를 확인하시기 바랍니다.)
[Dijkstra 알고리즘]
[알고리즘] Dijkstra 알고리즘
Dijkstra 알고리즘 - 정의 Dijkstra 알고리즘은 하나의 정점에서 나머지 정점까지의 최단 거리(경로)를 구하는 알고리즘입니다. 정점 사이에 간선이 존재하고, 간선마다 가중치(=비용)가 있습니다. 특
soso-yw.tistory.com
[Bellman-Ford 알고리즘]
앞으로 포스팅할 계획입니다.
지금까지 네트워크 계층에 대해 알아봤습니다!
다음 시간에는 전송 계층에 대해 알아보겠습니다.
'CS 전공지식 > 네트워크' 카테고리의 다른 글
| [네트워크] OSI 7계층(TCP) (3) | 2022.04.10 |
|---|---|
| [네트워크] OSI 7계층(전송 계층, UDP) (3) | 2022.04.02 |
| [네트워크] OSI 7계층(데이터 링크 계층) (3) | 2022.03.20 |
| [네트워크] OSI 7계층(물리 계층) (3) | 2022.03.15 |
| [네트워크] OSI 7계층 (3) | 2022.03.08 |



